This week I launched Rank the Things, a project in which people can vote to form a crowdsourced ranking of anything from pizza toppings to Pixar movies. I wanted to make it as simple to use as possible, so one is given a choice between just two options and has to pick which they prefer (or skip if they really can’t make a decision). To get a decent sample size, they’re given a bunch of opportunities to vote, but not too many to prevent one person from having too much influence on the final results.
Of course, there is the challenge of how to take all these votes and turn them into a ranking. The simplest way is to divide the number of votes for something over its total matchups, but that runs into the problem that there isn’t necessarily going to be a balanced strength of schedule. For instance, as of this writing, about three times as many people have weighed in on pepperoni vs. banana peppers as they have banana peppers vs. black olives. Therefore, I opted to go for a maximum likelihood estimation instead, which adds some complexity but isn’t excessively fancy.
A Brief Overview
Our ultimate goal is to find a numerical rating for each item that best fits the voting data. We assume that for any two things being compared, the odds that the first one would be chosen is equal to a/(a+b), where a is the rating of the first item and b is the rating of the second. Given that there are many different matchups, there is no way to adjust the numbers such that all the percentages align perfectly, but we can use a bit of math to provide a best fit. To go back to a previous example, banana peppers going up against pepperoni many times isn’t going to hurt the former’s rating as much, since we already expected it to not do so well against such a popular topping.
Finally, to make things more human-readable, I take the log of these values and adjust them to make the average rating 5. I do this since 5 is kind of an average number, and it means that ratings should stay within the 0-10 range. That being said, “0” and “10” don’t have any implicit meaning. Instead, what matters is the difference between any two ratings, not their absolute values. An 8 is expected to beat a 6 just as often as a 3 is expected to beat a 1. For more precise percentages, here’s how often something with a given rating is expected to beat something rated 5:
| Rating | Win % | Rating | Win % |
|---|---|---|---|
| 10 | 97.0 | 4.9 | 48.3 |
| 9 | 94.1 | 4.8 | 46.5 |
| 8 | 88.9 | 4.5 | 41.4 |
| 7 | 80.0 | 4 | 33.3 |
| 6.5 | 73.9 | 3.5 | 26.1 |
| 6 | 66.7 | 3 | 20.0 |
| 5.5 | 58.6 | 2 | 11.1 |
| 5.2 | 53.5 | 1 | 5.9 |
| 5.1 | 51.7 | 0 | 3.0 |
The Detailed Math
What we are trying to do is to maximise the probability that given a set of ratings, we will get the exact number of votes for each item that we received. If we define ri to be the rating of the i-th item, wij to be the number of times i beat j in a head-to-head matchup, we can calculate the total probability as:
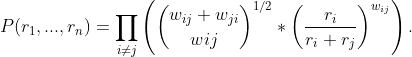
The first part of the product is because we don’t care what order each matchup is won by each thing, so we have to multiply by [number of games] choose [number of wins], square rooted as otherwise it would be duplicated. The second half is the probability that team i would be team j. We then have to multiply everything together to get an overall probability.
Since we need to maximise this product, we would take the derivative and set it to 0. To make things much easier, we can take the natural log and turn the log of a product into a sum of logs, as the logarithm is an increasing function and we aren’t dealing with negative numbers.
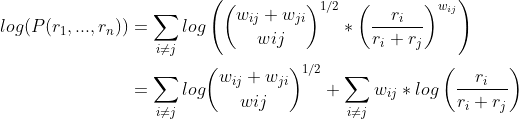
In this case, all the ratings are the independent variables, so we would take the partial derivatives with respect to all of them and set them to 0, giving us a system of equations for us to solve. As an example, for item 0, we would get
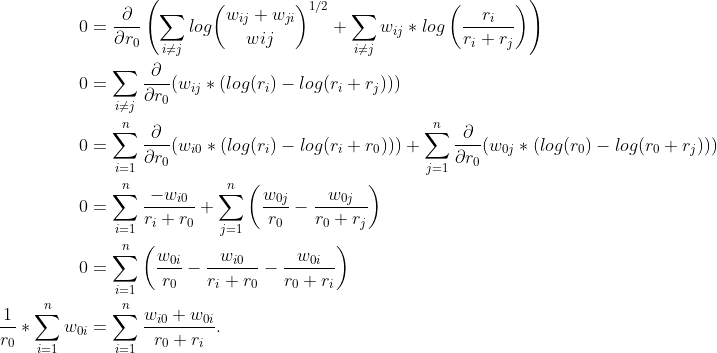
The sum of w0i is simply the total number of votes for item 0, and w0i + wi0 is the number of matchups between items 0 and i. Therefore, we can rewrite it as
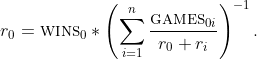
From here, we can use a numerical approximation to find the rating. The final step is to take the log base 2 of all the ratings and normalise it such that the average score is a 5. This is done purely to produce more human-readable numbers and to make it easier to compare the results. If you have something with a rating that is a points higher than something else, the odds that it would get voted would be 2a/(2a+1).
The full implementation of this can be found on Github. I might end up tweaking things a bit, but so far everything seems to work fairly well and sensibly. Feedback is appreciated, of course.
Leave a Reply